Golang 자료구조
이번 포스팅의 주제는 자료구조다.
👉자료구조
자료를 어떤 형태로 저장할 것인지를 나타낸다.
자료구조에는 크게 배열, 리스트, 트리, 맵 등이 있다.
리스트
배열과 함께 가장 기본적인 선형 자료구조이다.
선형 : 하나의 데이터의 다음 데이터는 하나만 있는 것. 비선형 : 하나의 데이터의 다음 데이터가 여러 개 (트리 등)
1
2
3
4
5
type Element struct {
value interface{} // 데이터 저장
Next *Element // 다음 요소의 주소
Prev *Element // 이전 요소의 주소
}
Next만 있으면 Linked List (싱글 리스트) , Prev도 있으면 Double Linke List라고 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
func main() {
v := list.New()
e4 := v.PushBack(4)
e1 := v.PushFront(1)
v.InsertBefore(3, e4)
v.InsertAfter(2, e1)
for e := v.Front(); e != nil; e = e.Next() {
fmt.Print(e.Value, " ")
}
fmt.Println()
for e := v.Back(); e != nil; e = e.Prev() {
fmt.Print(e.Value, " ")
}
}
| 행위 | 배열, 슬라이스 | 리스트 |
|---|---|---|
| 요소 삽입 | O(N) | O(1) |
| 요소 삭제 | O(N) | O(1) |
| 인덱스 요소 접근 | O(1) | O(N) |
요소 삽입이나 삭제가 많으면 리스트가 유리하고 랜덤 접근이 많은 경우 배열이 유리하다.
하지만!
데이터 지역성 (Data Locality)로 인해 성능이 항상 리스트가 좋은 것은 아니다.
데이터 지역성 : 데이터가 인접해 있을 수록 캐시 성공률이 올라가고 성능도 증가한다.
CPU 연산을 할 때 메모리에서 필요한 값만 가져오는 것이 아니라 근처 메모리까지 가져온다. 다음 연산이 근처에서 일어날 확률이 높기 때문에.
- 캐시 성공 : 근처 메모리에서 가져온 값이 이후 연산에 사용됨 -> 다시 가져올 필요 X
- 캐시 실패 : 근처 메모리에서 가져온 값이 이후 연산에 사용 안됨 -> 다시 가져와야 함
배열의 경우 캐시 성공이 많으므로 요소 수가 1,000개 이하로 적은 경우엔 리스트보다 배열이 빠르다.
10,000개 정도면 시스템에 따라 다르므로 리스트를 사용할 지 배열을 사용할 지 고민을 해보아야 한다.
큐
First In First Out (FIFO) 형식의 자료구조 ex ) 대기열
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
type Queue struct {
v *list.List
}
func (q *Queue) Push(val interface{}) {
q.v.PushBack(val)
}
func (q *Queue) Pop() interface{} {
front := q.v.Front()
if front != nil {
return q.v.Remove(front)
}
return nil
}
func NewQueue() *Queue {
return &Queue{list.New()}
}
func main() {
queue := NewQueue()
for i := 1; i < 5; i++ {
queue.Push(i)
}
v := queue.Pop()
for v != nil {
fmt.Printf("%v -> ", v)
v = queue.Pop()
}
}
스택
Last In First Out (LIFO) 형식의 자료구조
ex ) 함수 콜스택
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
type Stack struct {
v *list.List
}
func NewStack() *Stack {
return &Stack{list.New()}
}
func (s *Stack) Push(val interface{}) {
s.v.PushBack(val)
}
func (s *Stack) Pop() interface{} {
back := s.v.Back()
if back != nil {
return s.v.Remove(back)
}
return nil
}
func main() {
stack := NewStack()
books := [5]string{"어린왕자", "겨울왕국", "노인과바다", "발간머리앤", "짱구"}
for i := 0; i < 5; i++ {
stack.Push(books[i])
}
val := stack.Pop()
for val != nil {
fmt.Printf("%v -> ", val)
val = stack.Pop()
}
}
링
맨 끝과 맨 앞이 연결된 자료구조
일정한 갯수만 사용하고, 오래된 요소가 지워져도 되는 경우에 사용
ex) 실행 취소 기능, 고정된 길이 리플레이 기능(POTG 등)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
func main() {
r := ring.New(5)
n := r.Len()
for i := 0; i < n; i++ {
r.Value = 'A' + i
r = r.Next()
}
for j := 0; j < n; j++ {
fmt.Printf("%c ", r.Value)
r = r.Next()
}
fmt.Println()
// 역순 출력
for j := 0; j < n; j++ {
fmt.Printf("%c ", r.Value)
r = r.Prev()
}
}
Map
키와 값 형태로 데이터를 저장하는 자료구조다.
언어에 따라 딕셔너리, 해쉬테이블, 해쉬맵이라 부른다.
삽입, 삭제, 조회가 다 O(1)이다. 대신 메모리를 많이 먹는다.
Map의 원리
해시 함수의 동작
해시 : 잘게 부순다. (해시 포테이토)
- 같은 입력이 들어오면 같은 결과가 나온다.
- 다른 입력이 들어오면 되도록 다른 결과가 나온다.
- 입력값의 범위는 무한대, 결과는 특정 범위를 갖는다.
일반적으로 나머지 연산 (모듈라 연산)을 주로 사용한다.
”+”, “X” 등은 양방향 연산이라 역을 통해 원본을 알 수 있다.
ex) 1+3 = 4 -> 4-3 = 1
모듈라연산은 원본을 알 수 없으므로 보안성이 좋다.Map의 종류
- Hash Map
해쉬키에 따라 미리 많이 할당이 필요하지만 속도가 빠르다.- Sorted Map
이분탐색등을 통해 key값에 해당하는 곳에 value를 입력한다.
메모리는 적게 쓰지만 속도가 별로다
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
const HashKey = 10
func hash(d int) int {
return d % HashKey
}
func main() {
m := [HashKey]string{}
m[hash(23)] = "송하나"
m[hash(259)] = "바다"
fmt.Printf("%d = %s \n", 23, m[hash(23)])
fmt.Printf("%d = %s \n", 259, m[hash(259)])
}
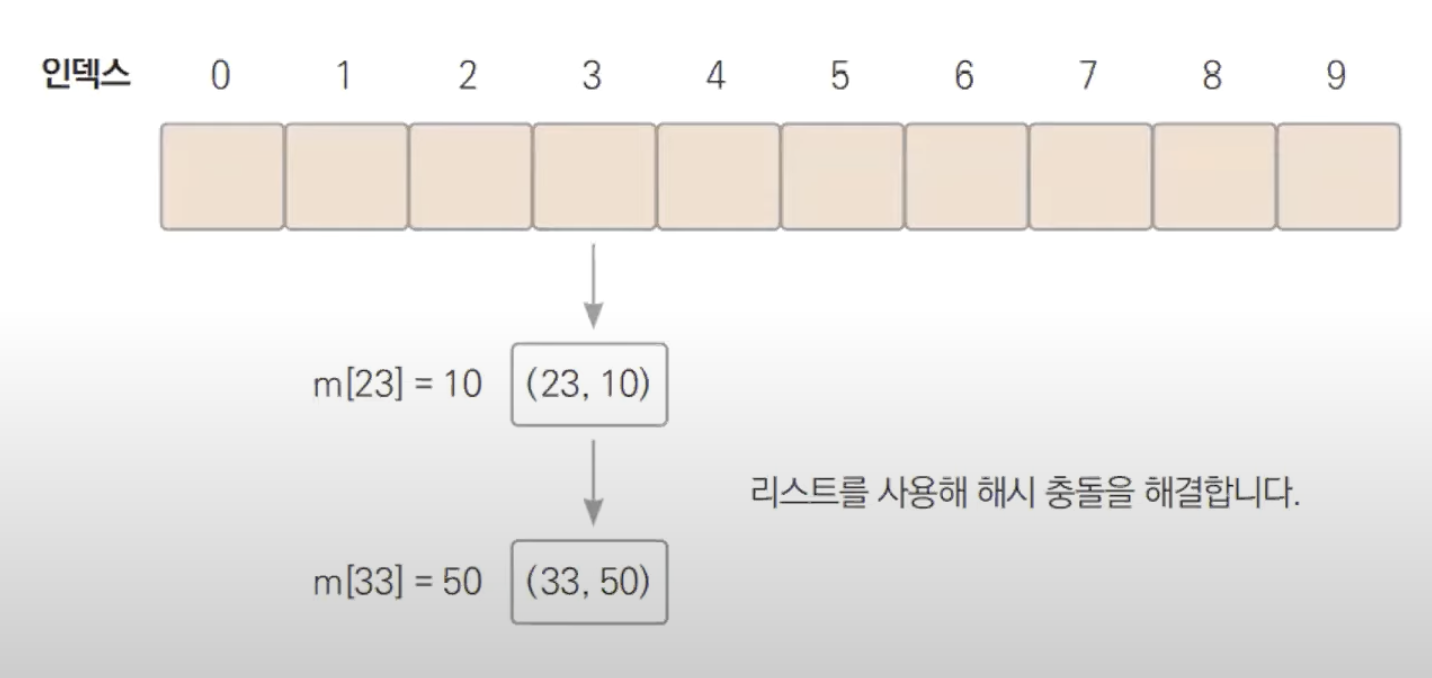
해시 충돌
위와 같이 map을 만들 경우 23과 33이 모듈라 연산 시 같은 값이 나와 덮어쓰기가 될 것이다.
이런 경우를 대비해 리스트를 사용해 해시 충돌을 해결한다.
배열의 값을 Key와 Value를 같이 저장하는 리스트로 생성하여 모듈라 연산 결과의 인덱스에서 해당 key값의 노드를 찾아 value를 반환한다. 이렇게 하여도, 전체 크기에 비해서 한없이 작은 루프를 돌게 되므로 O(1)에 근접한다.